Nvidias neue GeForce RTX 30-Serie stellt einen ordentlichen Leistungszuwachs in Aussicht. Und das, obwohl der Grundaufbau von Ampere eigentlich identisch zum Vorgänger Turing ist. Welche Faktoren für das Leistungsplus verantwortlich sind, soll hier kurz erklärt werden.
Nachdem Nvidia die neuen Grafikkarten der RTX 3000 Serie nur im Video mit Ausblick auf deren Leistung vorgestellt hatte, sind mittlerweile auch genauere Infos zur genutzten Technik bekannt. Interessant ist hier, dass der Chip-Hersteller die neue Generation eigentlich nur mit kleinen, aber effektiven Anpassungen leistungsfähiger machen konnte.
Der Aufbau von Ampere
Schaut man sich die Daten an, dann springt einem sofort ins Auge, dass sich die Anzahl der Streaming Multiprocessors (SM) massiv gesteigert hat. Das ehemalige Top-Modell, die RTX 2080 Ti, setzt auf 4.352 Cuda Cores. In der neuen Generation wird sie sogar von der RTX 3070 übertrumpft, welche derer 5.888 besitzt. Woher dieser Sprung kommt, ist eigentlich einfach erklärt und lässt sich am besten im Vergleich zwischen der RTX 2080 Ti und der RTX 3080 aufzeigen. Beide Grafikkarten setzten sechs Graphics Processor Cluster (GPC), welche die Streaming Multiprocessors (SM) und Texture Processing Cluster (TPC) beinhalten. Beide genannten Grafikkarten besitzen sechs GPCs sowie 68 SM.
| RTX 3090 | RTX 3080 | RTX 3070 | RTX 2080 Ti | |
| GPU | GA102 | GA102 | GA104 | TU102 |
| GPC | 7 | 6 | ? | 6 |
| SM | 82 | 68 | 46 | 68 |
| FP32-ALUs pro SM | 128 | 64 | ||
| FP32-ALUs | 10.496 | 8.704 | 5.888 | 4.352 |
| INT32-ALUs pro SM | 64 | |||
| INT32-ALUs | 5.248 | 4.352 | 2.944 | 4.352 |
Der entscheidende Unterschied liegt nun im Aufbau der Streaming Multiprocessors. Während bei Turing, also konkret auch der 2080 Ti, jeder SM 64 FP32-ALUs und 64 reine INT32-ALUs besitzt, besitzt Ampere nun pro SM 64 FP32-ALUs sowie 64 ALUs, welche Floatin-Point und Integer-Berechnungen durchführen können. Somit gibt es also pro SM 128 FP32-ALUs. Beachtet werden muss dabei aber, dass Integer- und Floating-Point-Berechnungen nicht parallel durchgeführt werden können. Die doppelte Anzahl der Cuda Cores der RTX 3080 gegenüber der RTX 2080 Ti ist also nur ein theoretischer Wert und dann gültig, wenn reine FP-Berechnungen stattfinden. Der Leistungszuwachs der GeForce RTX 3000 GPUs ist damit also auch von den Spielen abhängig bzw. davon, was für Berechnungen stattfinden.

Die gesteigerte Anzahl an FP32-ALUs hat aber auch zur Folge, dass die Komplexität der SM steigt. Das war auch mit der Grund, warum man sie in den letzten Generationen schrittweise verringerte (Kepler 192, Maxwell 128, Turing 64). Damit also bei Ampere eine gute Auslastung erreicht werden kann, hat Nvidia die Leistung des Shared Memory erhöht und den L1-Cache der Streaming Processors erhöht. Die Bandbreite wurde von 116 GB/s auf 219 GB/s gesteigert und der Cache von 96 KB auf 128 KB gewachsen.
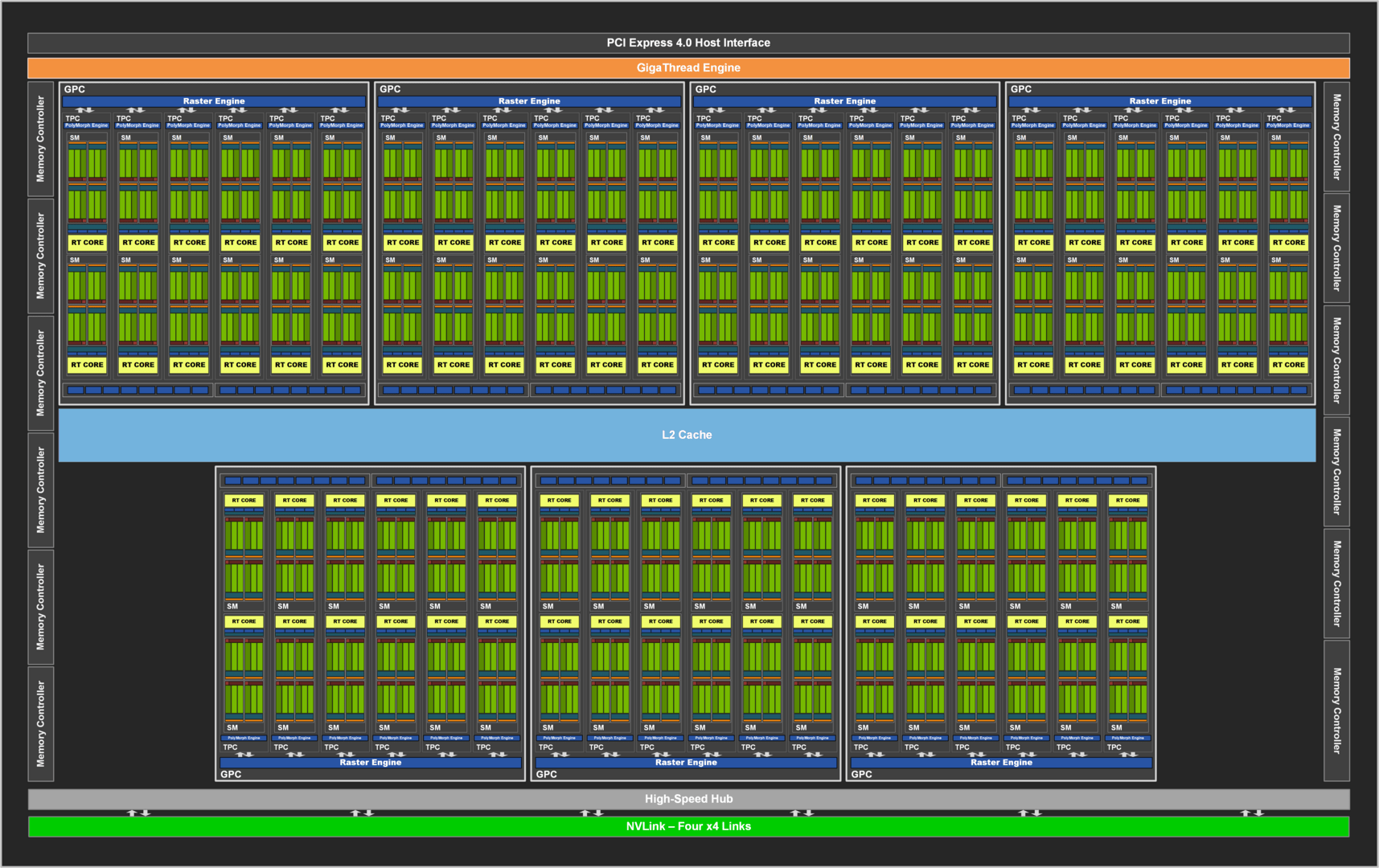
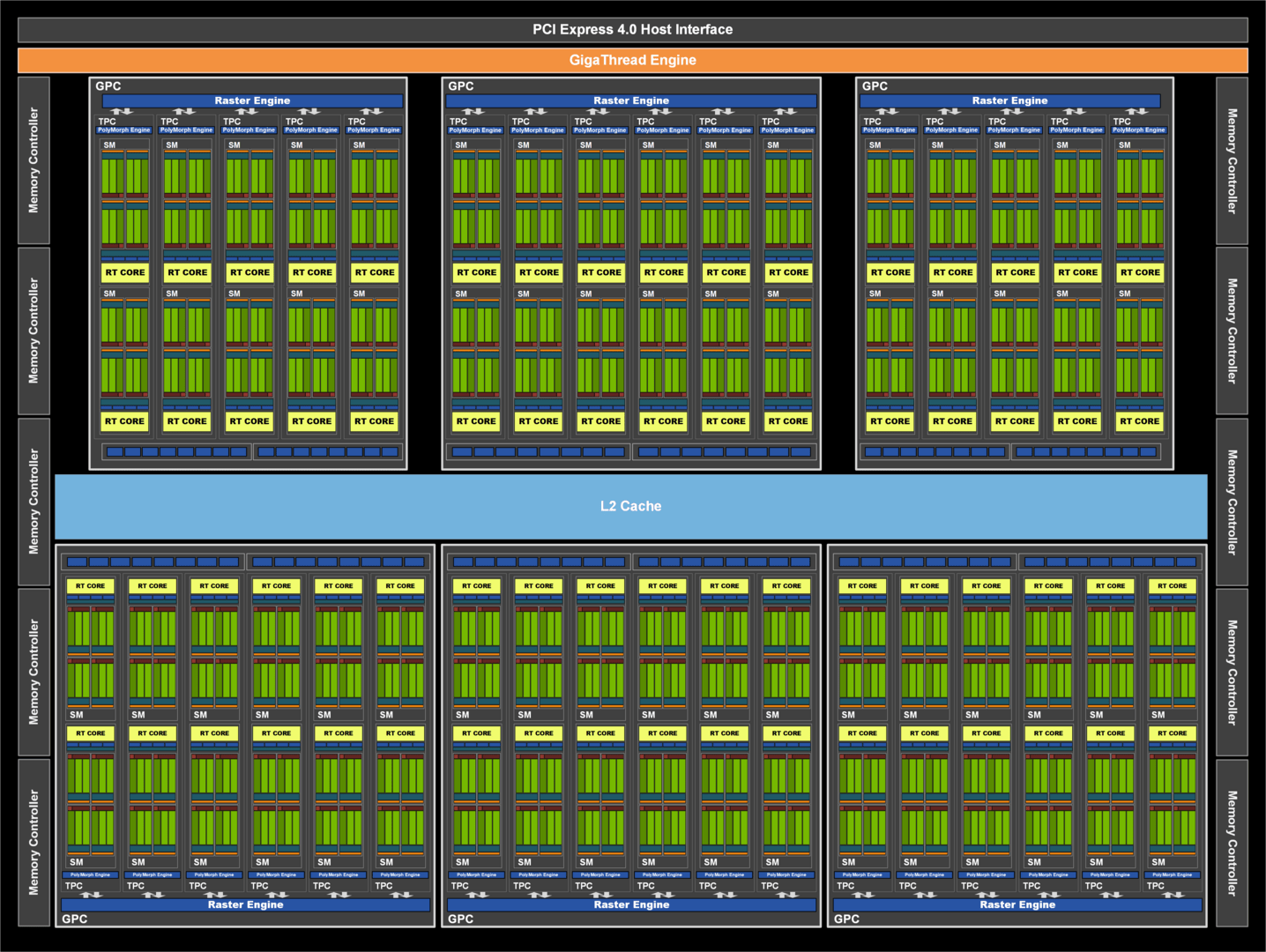
Nvidia GA102: links Vollausbau auf der RTX 3090, rechts teildeaktiviert auf der RTX 3080
Einen weiteren Unterschied gibt es bei den ROPs. Zuvor waren diese am Speicherinterface angebunden, sodass ihre Anzahl mit dessen Ausbau zusammenhing. In der neuen Generation sind die ROPs nun in den GPCs untergebracht. Pro GPC sind zwei ROP-Partitionen vorhanden, welche wiederum bis zu acht ROPs enthalten. Somit kann Ampere hier insgesamt mehr bieten als noch Turing. Die Leistung der ROPs selbst sollte allerdings identisch bleiben.
Leistungsvergleiche von Nvidia
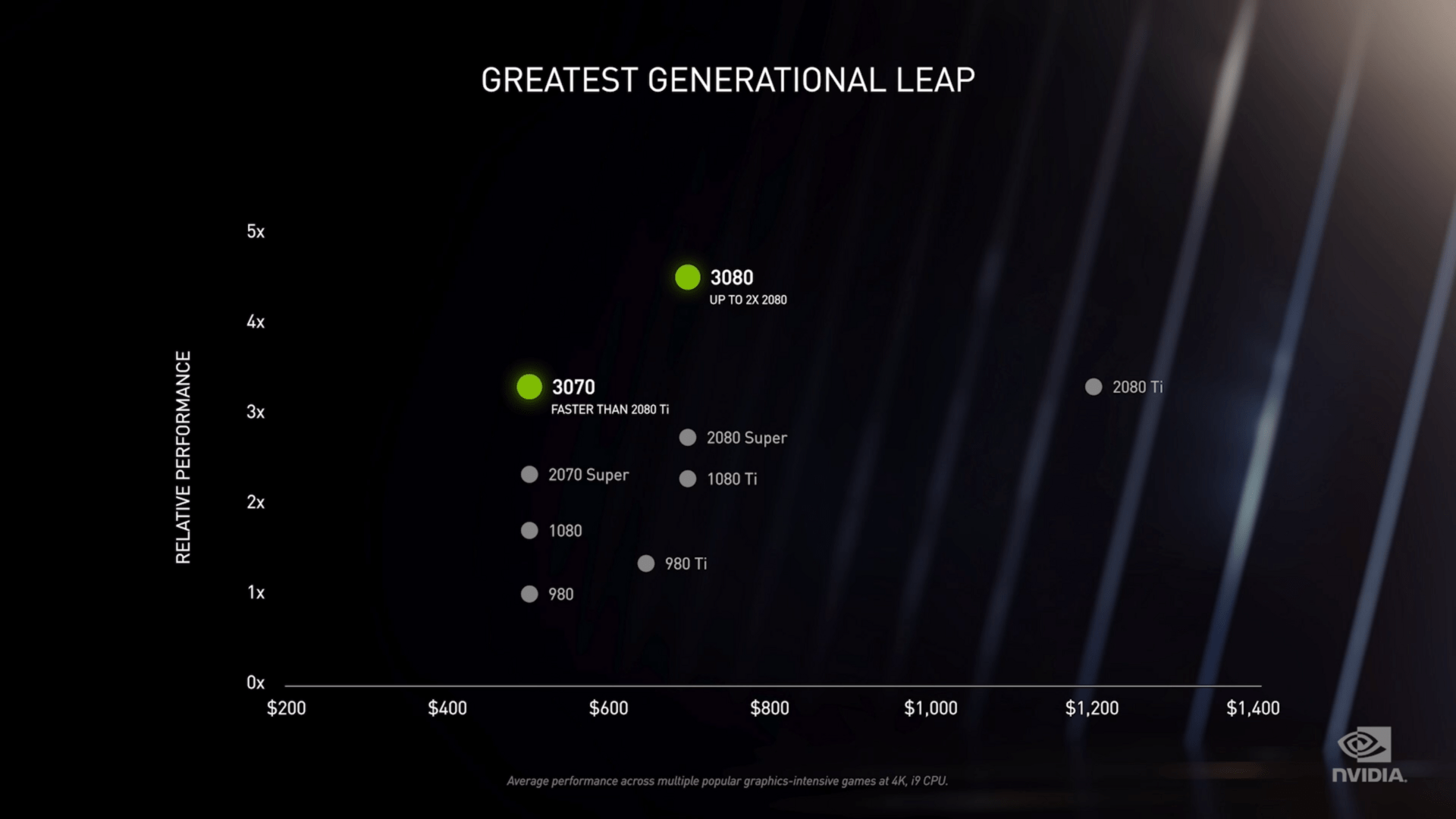
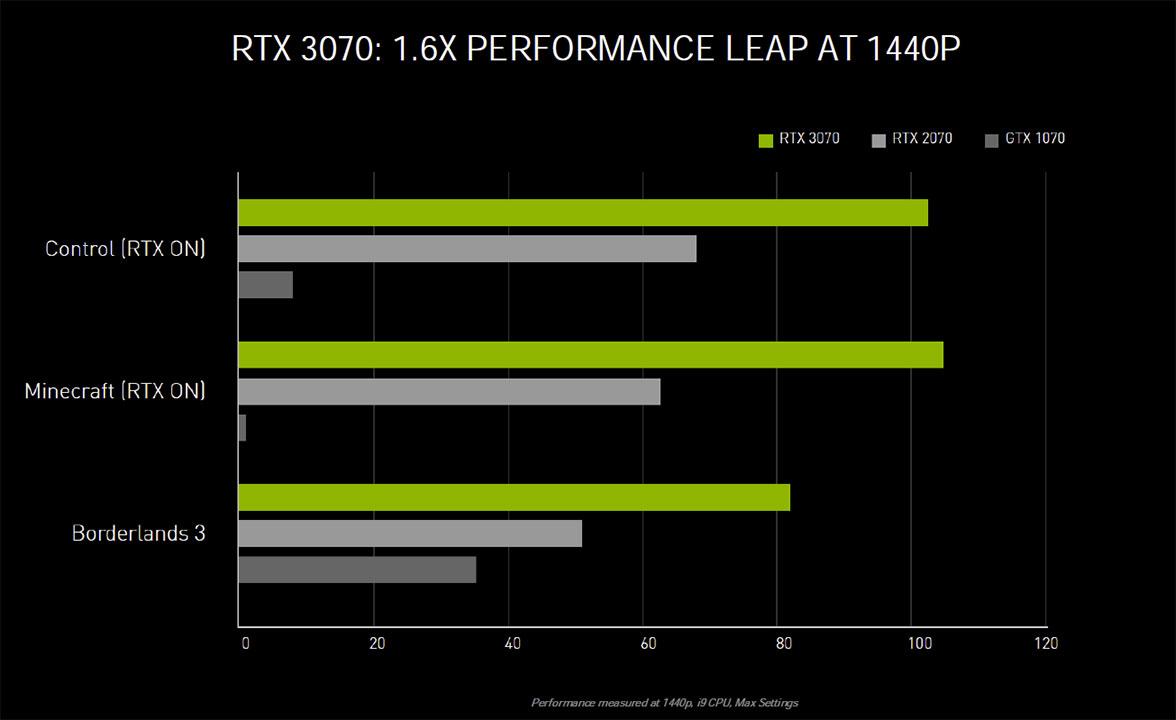
Natürlich liefert der Hersteller auch eigene Vergleiche der neuen Modelle. Bei den beiden kleineren Grafikkarten führt man sogar den Vergleich mit dem jeweiligen Turing- und Pascal-Vorgänger an. Die RTX 3070 ist für 1440p Gaming vorgesehen und startet mit einer UVP von 499€. Der Hersteller sprach bereits davon, dass sie schneller sein soll als eine RTX 2080 Ti. Es ist also kein Wunder, dass man die RTX 2070 leicht schlagen kann. Die GTX 1070 fällt weit ins Hintertreffen.
Wenn bereits die RTX 3070 die RTX 2080 Ti schlägt, ist also noch weniger verwunderlich, dass die RTX 3080 die RTX 2080 deutlisch schlagen kann bzw. soll. Für 699€ erhält man nun eine Grafikkarte, welche bereits 4K Gaming bewältigen können soll.
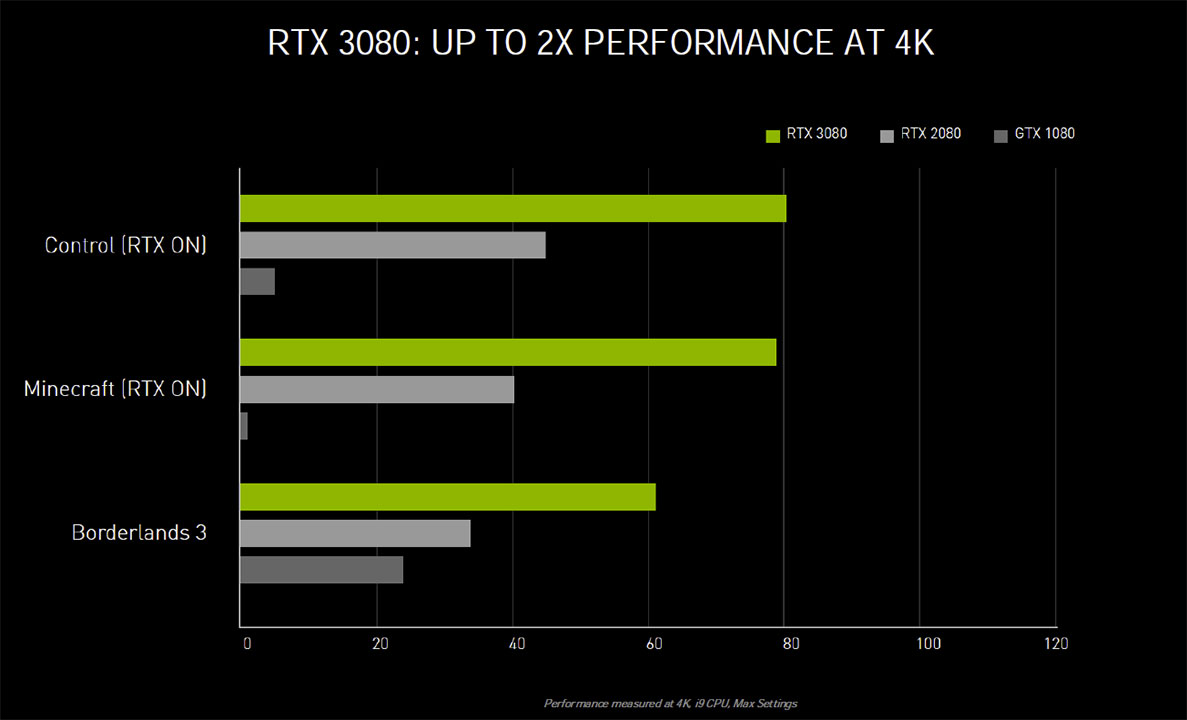
Die RTX 3090 hat eigentlich keinen Vorgänger und wird daher der RTX Titan gegenübergestellt. Mit 1499€ ist sie aber ebenfalls nicht billig, aber günstiger. Bei der Leistung zeigt sie sich aber auch besser aufgestellt, sodass auch hier ein besseres Preis-Leistungs-Verhältnis geboten wird.
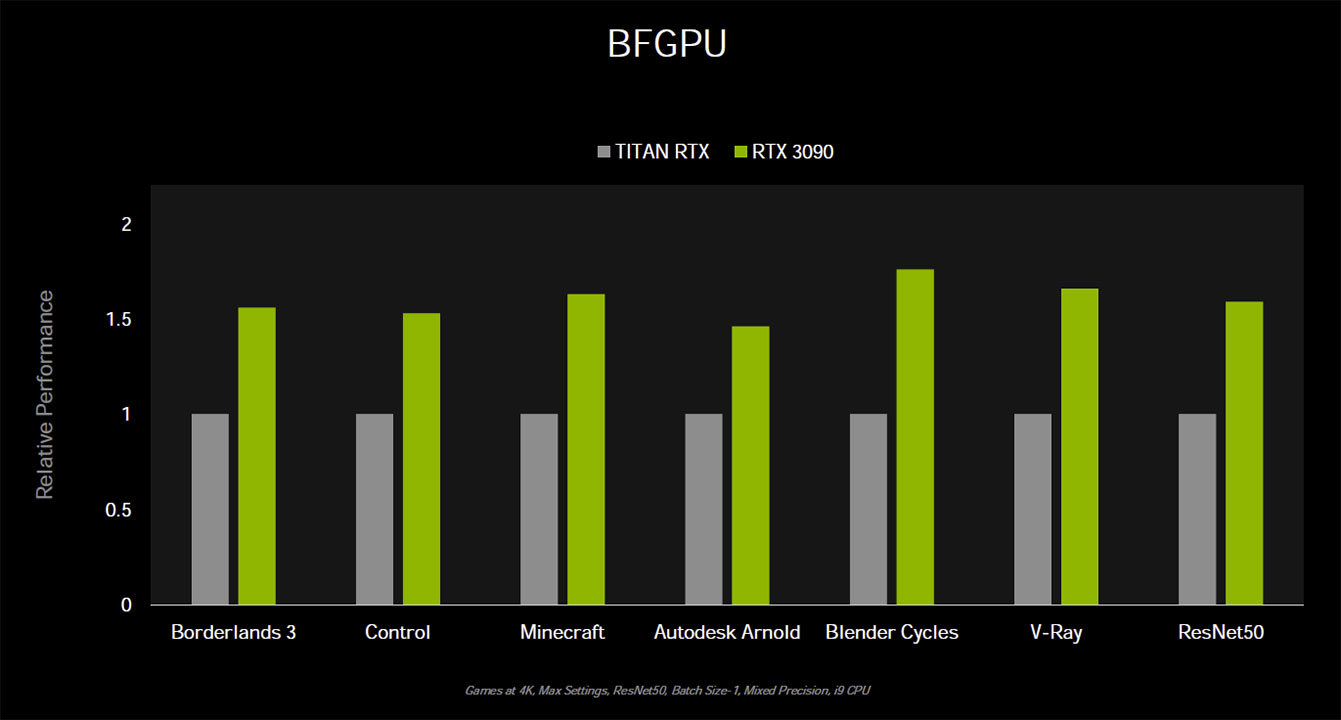
Raytracing
Die Überarbeitung der Raytracing-Kerne soll ebenfalls eine ordentliche Leistungssteigerung nach sich gezogen haben. Die größte Schwachstelle von Turing, die Schnittstellenprüfung (Ray Traversal), beherrscht Ampere doppelt so schnell. Weiterhin können die RT-Kerne der zweiten Generation nun Raytracing mit Motion Blur berechnen. Insgesamt soll die Geschwindigkeit dadurch um den Faktor 8 zunehmen. Abseits von Spielen kann man ebenfalls mit einem Leistungsplus rechnen. Blender profitiert angeblich um den Faktor 5 und generell ist die Rede von einer Steigerung von 70 bis 130%.
| RTX 3090 | RTX 3080 | RTX 3070 | RTX 2080 Ti | |
| GPU | GA102 | GA102 | GA104 | TU102 |
| RT-Kerne | 82 2nd Gen | 68 2nd Gen | 46 2nd Gen | 68 1st Gen |
| Tensore-Kerne | 382 3rd Gen | 272 3rd Gen | 184 3rd Gen | 544 3rd Gen |
Potenter wurden auch die Tensor-Kerne. Deren Anzahl hat zwar abgenommen, da sie allerdings viermal so schnell sein sollen, soll Ampere auch hier mit einem Sieg gegen Turing hervorgehen. Selbst die RTX 3070 soll eine höhere KI-Leistung als die RTX 2080 Ti bieten.

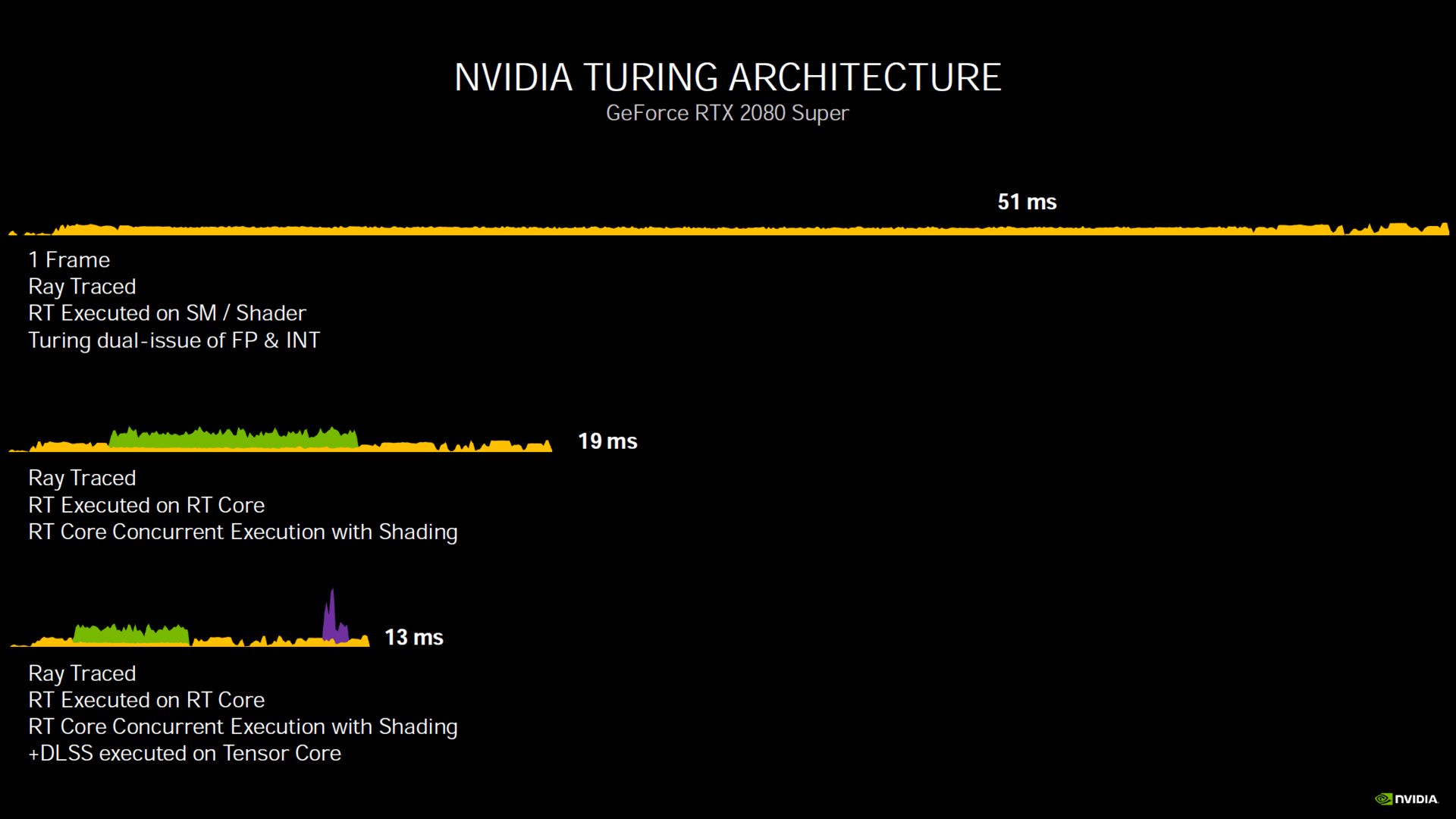
Als weiteren Vorteil kann man bei Ampere nennen, dass FP32-ALUs, RT-Kerne und Tensor-Kerne gleichzeitig genutzt werden können, was bei Turing nicht der Fall ist. In Nvidias aufgezeigten Beispiel kann die RTX 3080 gegenüber der RTX 2080 ein Frame bei gleichzeitiger Nutzung aller drei Berechnungen um 94% schneller fertigstellen, da dies bei Turing schlicht nicht mögich ist. Aber auch in den einzelnen Szenarien verzeichnet Ampere einen deutlichen Leistungsgewinn.
RTX IO
Mit RTX IO führt Ampere die Nutzung von Microsofts kommender DirectStorage-API ein. Die Technologie soll den üblichen Verarbeitungsweg vom Speicherort eines Spiels über die CPU, den RAM sowie der PCIe-Schnittsltelle abkürzen. Benötigt werden dazu allerdings schnelle NVMe-Laufwerke. Die Abkürzung sieht einen Direktzugriff der Grafikkarte über das PCIe-Interface vor. Da Ampere PCIe Gen4 beherrscht kann bei passendem Unterbau und Kompression also mit bis zu 14 GB/s gelesen werden, wobei die CPU und Arbeitsspeicher deutlich entlastet werden.
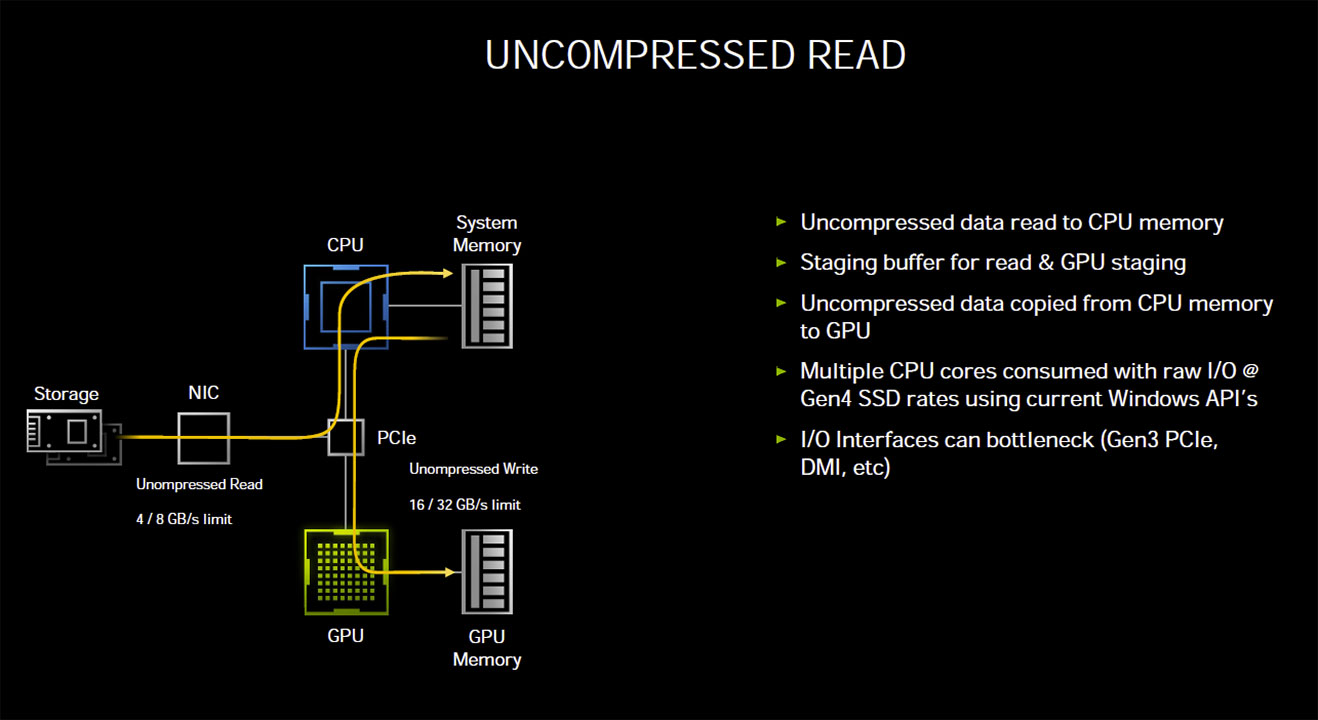

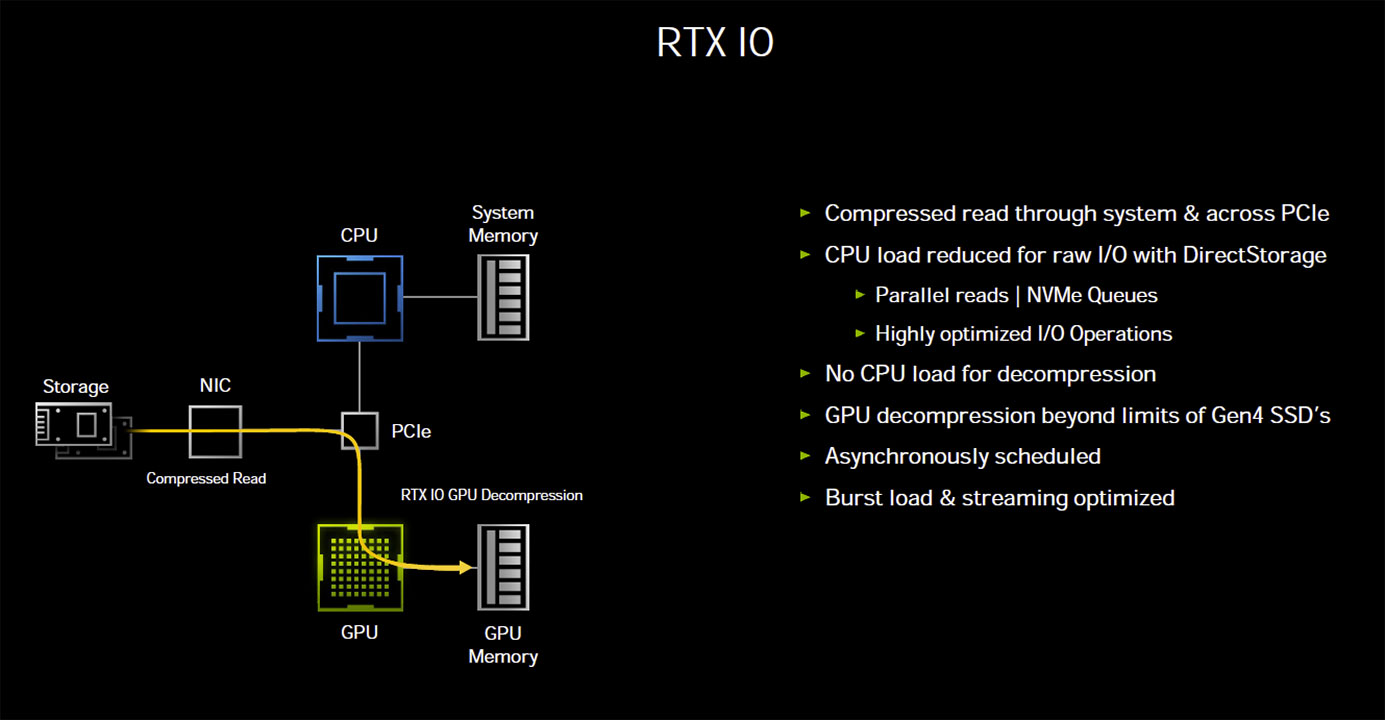
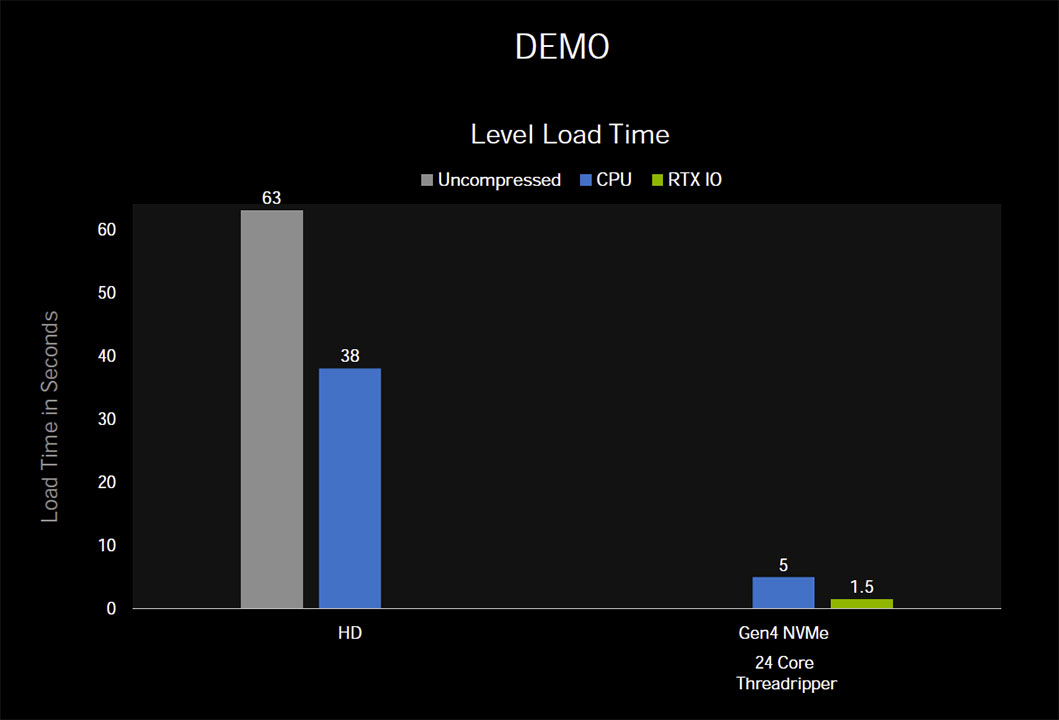
Die Tech-Demo von Nvidia zeigt hier erstaunliche Resultate. Unkomprimiert und über den klassischen Weg braucht das Laden der Marbles-Techdemo von einer HDD 60 Sekunden. Wird die Komprimierung genutzt steigt die CPU-Last, aber die Zeit verkürzt sich auf 37 Sekunden. Der Einsatz einer Gen4 NVMe SSD lässt die Zeit auf 5 Sekunden sinken, benötigt durch die Kompression aber auch 24 Kerne unter Vollast. RTX IO soll hingegen nur 1,6 Sekunden und das bei keiner CPU-Last benötigen. Aktuell wäre diese Technologie nur mit einem AMD System mit B550 oder X570 Mainboard und Matisse oder Renoir CPU nutzbar. Da Microsoft die DirectStorage-API erst 2021 einführt, könnte dann aber Intels Rocket Lake-S verfügbar sein.
Effizienz und Kühlung
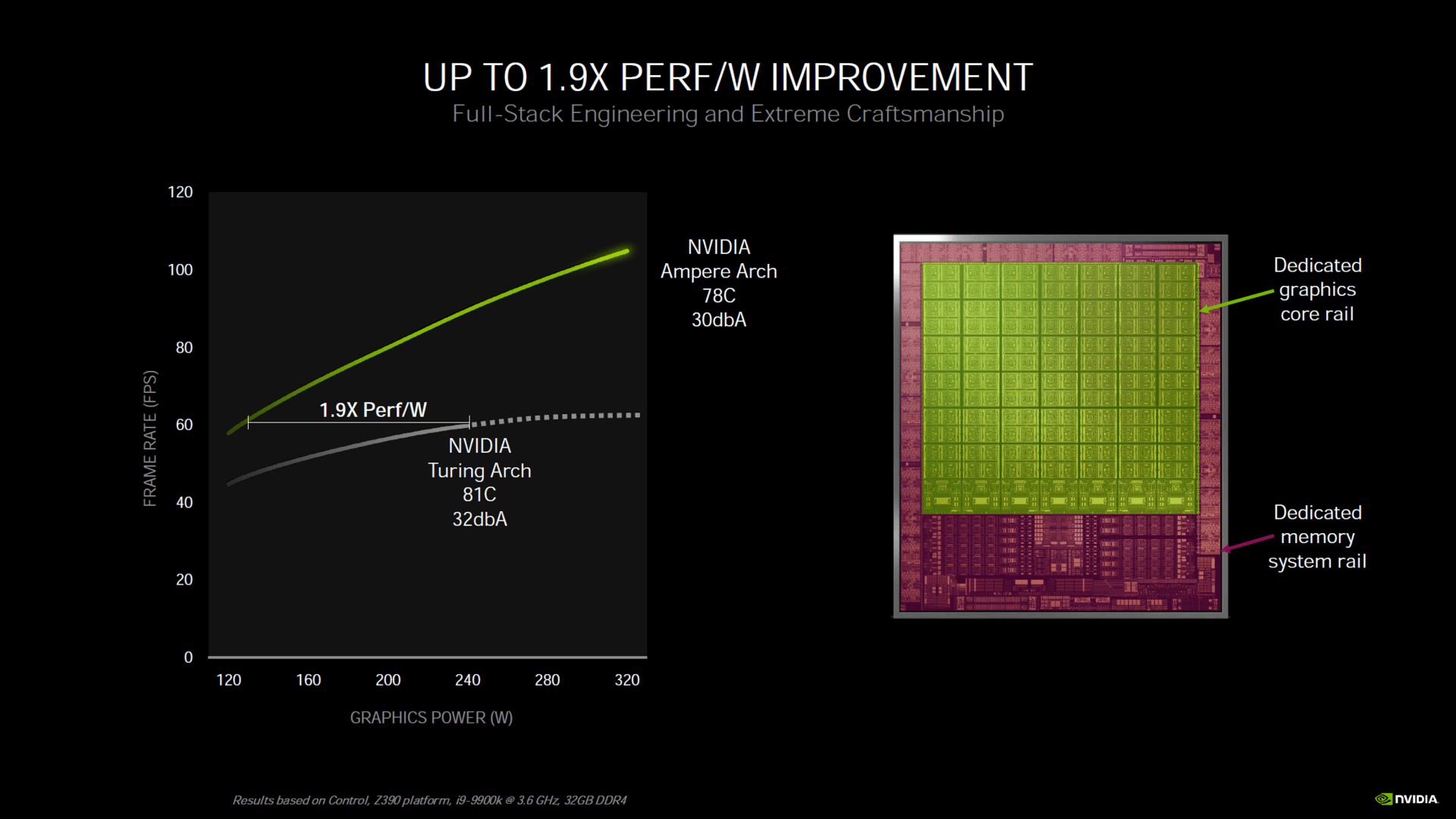
Setzt man einen Framelimiter ein, soll die RTX 3080 90% mehr Leistung pro Watt bieten als eine Turing Grafikkarte. Das liegt natürlich auch daran, dass die Fertigung nun in 8nm und nicht mehr in 12nm erfolgt. Zudem wird Turing im genannten Szenario mehr ausgelastet als Ampere. Eine Trennung der Spannungsversorgung von Rechenkernen und Speichersystem soll ebenfalls Energie sparen, da nicht immer beide Bereiche gleichzeitig ausgelastet werden.
Für besonderes Aufsehen hat das PCB der Founders Edition gesorgt. Es ist nicht nur deutlich kürzer als zuvor, sondern auch besonders gestaltet. Die Kompaktheit begründet der Hersteller damit, dass GDDR6X, PCIe 4.0 und HDMI 2.1 von kurzen Signalwegen profitieren. Die Aussparung am Ende ist der Kühlung geschuldet. In dem Bereich wird das Lamellen-Paket komplett durchströmt und die erwärmte Luft somit Richtung CPU-Kühler geleitet.


Dabei kommen wie bei den letzten Founders Editions ebenfalls zwei Lüfter zum Einsatz, jedoch sitzen diese nicht unmittelbar nebeneinander. Es herrscht sozusagen ein Versatz, denn der rechte sitzt mehr oder weniger auf Höhe der Backplate. Das Prinzip kommt dabei nur bei der RTX 3080 und der RTX 3080 zum Einsatz. Die RTX 3070 setzt auf einen eher konventionellen Kühler. Genannt werden daher auch nur Leistungswerte zum beschriebenen Konzept.
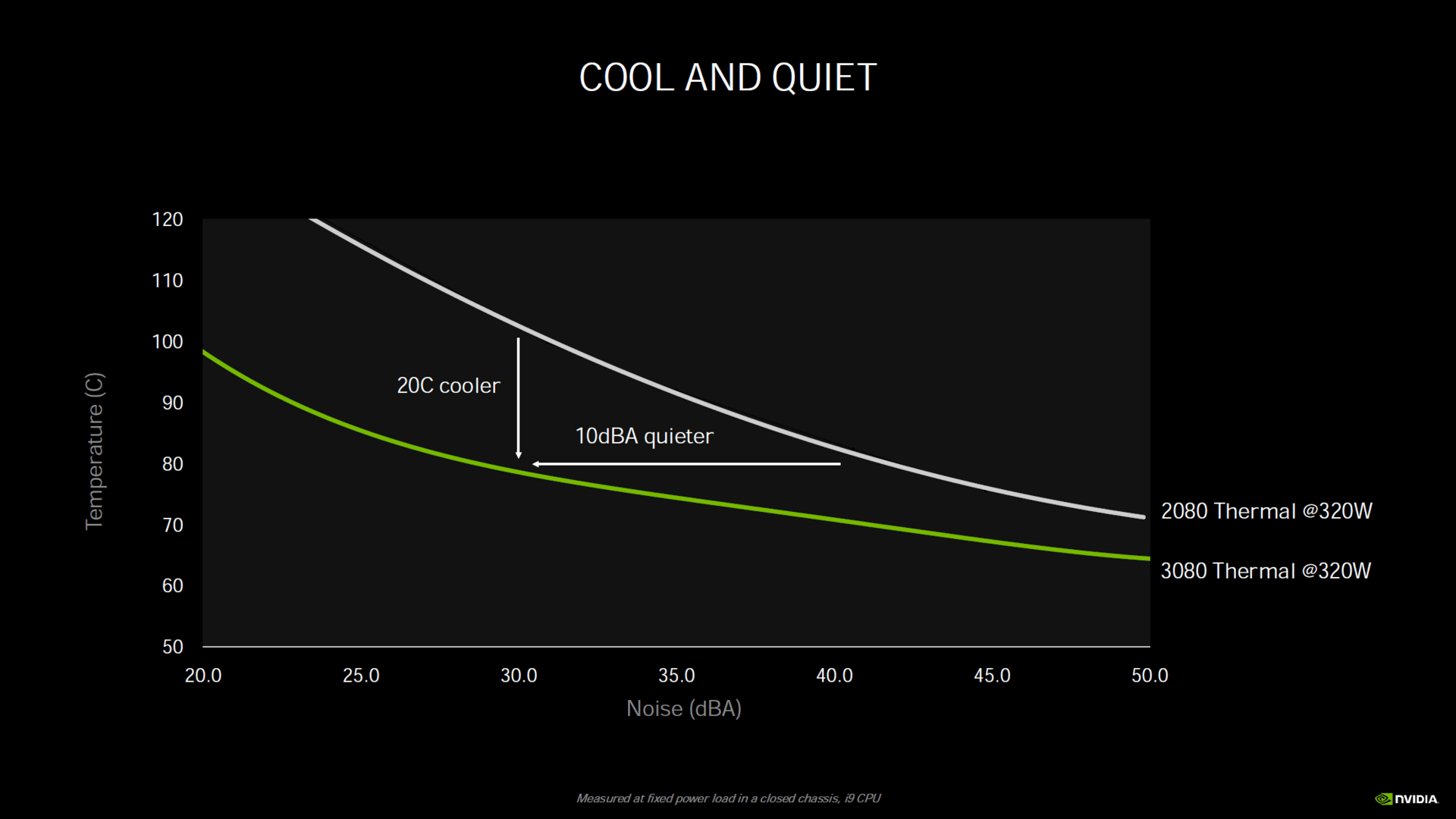

Eine RTX 3080 soll demnach bei 320W und gleicher Lautstärke 20°C Kühler als eine RTX 2080 FE arbeiten oder 10dB leiser bei gleicher Temperatur. Der größere Kühler (drei, statt zwei Slot) der RTX 3090 soll bei 350W 20 Dezibel leiser arbeiten als eine vergleichbare RTX 2080 Ti FE.
Quelle: Nvidia











{kind=link}